原文地址:https://jhalon.github.io/chrome-browser-exploitation-2/
在我之前的文章《Chrome浏览器开发第1部分:V8和JavaScript内部原理介绍》中,我们第一次深入探讨了浏览器利用的背景知识,涉及了一些基础知识以及必需知道的复杂主题。我们主要讨论了JavaScript和V8在底层是如何工作的,通过探索对象、Map和Shape是什么,这些对象是如何在内存中结构化的,我们还讨论了一些基本的内存优化,如指针标记和指针压缩。我们还谈到了编译器工作流程、字节码解释器和代码优化。
现在,如果你还没有读过我之前的文章——那么我强烈建议你去读一下。否则,您可能会困惑并完全不熟悉本文中介绍的一些主题,因为我们基本上是以第1部分中介绍的知识为基础,并在此基础上进一步扩展。
在今天的博客文章中,我们将返回编译器工作流程,并将进一步扩展我们谈到的一些概念,例如V8的字节码,代码编译和代码优化。总体而言,在这篇文章中,我们将深入了解Ignition,SparkPlug和TurboFan发生的事情,因为它们的某些“特性”如何导致可利用的错误方面的理解至关重要。
本篇文章将讨论以下主题:
- Chrome 安全模型
- 多进程沙箱架构
- V8 的隔离和上下文
- Ignition解释器
- 了解寄存器机
- 理解 V8 的字节码
- Sparkplug
- 1:1 Mapping
- TurboFan
- 即时编译 (JIT)
- 推测优化和类型保护
- 反馈格栅
- “节点海”中间表示(IR)
- 常见优化
- Typer
- Rang Analysis
- 边界检查消除 (BCE)
- 冗余消除
- 其他优化
- 控制优化
- 别名分析和全局值编号
- DeathCode消除 (DCE)
- 常见的 JIT 编译器漏洞
好了,结束了这一长串可怕的复杂话题,让我们深吸一口气,开始吧
注意:大多数(如果不是全部的话)突出显示的代码路径都是可点击的链接。使用这些链接可以进入Chromium源代码的相关部分,这样您就可以更仔细地检查代码,并跟随文章。另外,花点时间阅读代码注释。Chromium源代码虽然复杂,但有一些非常好的注释,可以帮助您理解代码的哪一部分以及它的功能。
Chrome安全模型
在深入了解编译器工作流程的复杂性、它如何进行优化以及bug可能出现在哪里之前,我们首先需要后退一步,看看更大的视野。虽然编译器工作流程在JavaScript执行中扮演着重要的角色,但它只是整个浏览器体系结构中的一块拼图。
正如我们所看到的,V8可以作为一个独立的应用程序运行,但当它作为一个浏览器整体运行时,V8实际上是嵌入到Chrome中,然后通过绑定被另一个引擎使用。正因为如此,我们需要了解应用程序中的JavaScript代码是如何处理的,因为这些信息对于我们理解浏览器中的安全问题至关重要。
为了让我们看到更大的图景,并把所有的拼图放在一起,我们需要从理解Chrome安全模型开始。这篇博客文章系列终究是一次关于浏览器内部结构和利用的旅程。因此,为了更好地理解为什么某些错误比其他错误更微不足道,以及为什么仅仅利用一个bug可能不会导致直接的远程代码执行,我们需要了解Chromium的架构。
如我们所知,JavaScript引擎是系统执行JavaScript代码不可或缺的一部分。一方面它们在使浏览器快速有效地发挥作用时发挥了重要作用,但另一方面他们也可能导致浏览器崩溃,应用程序挂起甚至安全风险。但是JavaScript引擎并不是浏览器可能会有问题或漏洞的唯一部分。许多其他组件,例如API或HTML和CSS渲染引擎所使用的也可能存在稳定性问题和漏洞,这些问题可能会被有意无意的利用。
现在,几乎不可能构建一个永远不会崩溃的JavaScript或渲染引擎。而且几乎不可能构建这些类型的引擎,以确保它们不存在漏洞- 尤其是因为这些组件中的大多数都以C ++的静态语言进行编程,以处理Web应用程序的动态性质。
那么,Chrome如何处理如此“不可能”的任务,即试图保持浏览器有效运行,同时还试图保持浏览器,系统及其用户的安全?通过两种方式,使用多进程架构和沙箱。
多进程沙箱架构
Chromium的多进程体系结构就是这样,一种使用多进程来保护浏览器免受不稳定性问题和错误的架构,这些问题可能来自JavaScript引擎,渲染引擎或其他组件。Chromium还可以通过仅允许某些进程相互通信来限制每个进程之间的访问。这种类型的体系结构可以看作是在应用程序中将内存保护和访问控件的结合。
一般来说,浏览器有一个主进程,它运行UI并管理所有其他进程——这被称为浏览器进程或简称浏览器。处理web内容的进程称为渲染进程进程或渲染器。这些渲染进程利用了一个叫做Blink的东西,它是Chrome使用的开源渲染引擎。Blink实现了许多其他帮助它运行的库,例如Skia,这是一个开源的2D图形库,当然还有用于JavaScript的V8。
现在,事情变得有点复杂了。在Chrome中,每个新窗口或选项卡都会在一个新进程中打开——通常是一个新的渲染进程。这个新的渲染进程有一个全局RenderProcess对象,用于管理与父浏览器进程的通信,并在窗口或选项卡中维护web页面或应用程序的全局状态。反过来,主浏览器进程将为每个渲染器维护一个相应的RenderProcessHost对象,该对象管理渲染器的浏览器状态和通信。
为了在这些进程之间进行通信,Chromium使用了遗留的IPC系统或Mojo。我不打算过多地讨论这些是如何工作的,因为老实说,Chrome的架构和通信方案本身可以是一篇单独的博客文章。我将把它留给读者,让他们按照链接进行自己的研究。
总的来说,谈话很便宜,计算能力很昂贵。为了帮助更好地可视化我们刚才解释的内容,下面这张来自Chromium开发团队的图片将为我们提供多进程体系结构的高级概述。
除了每个渲染器都在自己的进程中,Chrome还利用了通过沙箱限制进程访问系统资源的机会。通过沙盒每个进程,Chrome可以确保渲染器只能通过运行在主进程中的网络服务分派器访问网络资源。此外,它还可以限制进程对文件系统的访问以及对用户显示、cookie和输入的访问。
通常,如果攻击者在渲染器过程中获得远程代码执行,则限制了他们可以做什么。本质上,他们将无法对计算机进行持续更改或访问信息,例如其他窗口和选项卡中的用户输入和cookie,而无需利用或链接另一个错误以脱离该沙盒。
我不会在这里详细介绍,因为这将偏离当前的博客主题。但是我强烈建议您深入阅读Chromium Windows Sandbox Architecture文档,这样不仅可以理解设计原则,还可以更好地理解代理和目标进程通信方案。
这在实践中是怎样的呢?好吧,我们可以看到一个实际的例子,启动Chrome,打开两个选项卡,并启动进程监视器。最初我们应该看到Chrome有一个父进程或浏览器进程和一些子进程,就像这样。
现在,如果我们要查看主父进程,并将其与子进程进行比较,我们将注意到其他进程正在使用不同的命令行参数运行。在本例中,我们看到子进程(在右边)是呈现器类型的进程,并且与它的父浏览器进程(在左边)匹配。很酷,对吧
好吧,在介绍了所有这些之后,我知道你可能会问我,所有这些与V8和JavaScript有什么关系?好吧,如果你注意的话,当我提到chrome渲染引擎Blink时,你就会注意到一个关键点。这就是它实现V8的原因。
如果你像一个好学生那样花时间阅读了一些Blink文档,那么你就会对Blink有所了解。在文档中,它指出Blink在每个渲染器进程中运行,它有一个主线程来处理JavaScript、DOM、CSS、样式和布局计算。此外,Blink还可以创建多个工作线程来运行额外的脚本、扩展等。
一般来说,每个Blink线程都运行自己的V8实例。为什么?正如你所知,在一个单独的浏览器窗口或选项卡中,可能会有很多JavaScript代码在运行,不只是针对页面,而是针对广告、按钮等不同的iframe。同时,这些脚本和iframe都有单独的JavaScript上下文,必须有一种方法防止一个脚本操纵另一个脚本中的对象。
为了帮助将一个脚本上下文与另一个脚本上下文隔离开来,V8实现了所谓的隔离上下文(isolate and context),我们现在将讨论它。
V8的隔离上下文
在V8中,isolation只是一个实例或虚拟机的概念,它代表一个JavaScript执行环境;包括堆管理器、垃圾回收器等。在Blink中,隔离和线程具有1:1的关系,其中一个隔离与主线程关联,另一个隔离与工作线程关联。
Context对应于一个全局根对象,该对象保存了VM的状态,并用于在V8的单个实例中编译和执行脚本。粗略地说,一个窗口对象对应一个上下文,由于每个frame 都有一个窗口对象,因此在渲染器进程中可能存在多个上下文。相对于隔离,隔离和上下文在隔离的生命周期中具有1:N的关系——其中特定的隔离或实例将解释和编译多个上下文。
这意味着每次需要执行JavaScript时,我们都需要通过GetCurrentContext()验证我们是否在正确的上下文中,否则我们将最终泄漏JavaScript对象或覆盖它们,这可能会导致安全问题。
在Chrome中,运行时对象V8::Isolate两个在V8/Inclups/V8-selic.h中实现,v8::Context对象在V8/include/v8-context.h中实现。根据我们所知道的,自上而下,我们可以可视化Chrome中的运行时和上下文本质,从而看起来如下:
如果你想了解更多关于这些隔离和上下文是如何深入工作的,那么我建议你阅读V8绑定的设计和V8嵌入入门。
Ignition Interpreter
现在,我们已经对Chromium的体系结构进行了一般概述,并了解所有JavaScript代码均未在同一V8引擎实例中执行,我们最终可以返回编译器工作流程并继续深入解析。
我们将从更深入地了解V8的解释器点火器开始。
作为第1部分的回顾,让我们回顾一下我们对V8编译工作流程的高级概述,以便我们知道我们在此工作流程中的位置。

我们已经在第1部分中介绍了令牌和抽象语法树(AST),并简要解释了如何在解释器中解析AST并将其转换为字节码。我现在要做的是介绍V8的字节码,因为解释器生成的字节码是组成任何JavaScript函数的关键构建块。此外,当Ignition编译字节码时,它还会在每次JavaScript函数运行时收集分析和反馈数据。然后,这些反馈数据被TurboFan用来生成JIT优化的机器代码。
但是,在我们开始理解字节码是如何构造的之前,我们需要首先理解Ignition是如何实现它的寄存器机的。原因是每个字节码都将其输入和输出指定为寄存器操作数,因此我们需要知道这些输入和输出将在堆栈上的哪个位置。这也将帮助我们进一步可视化和理解V8中产生的堆栈框架。
理解寄存器机
我们知道,Ignition解释器是一个基于寄存器的解释器,带有一个累加寄存器。这些寄存器实际上并不是人们所认为的传统机器寄存器。相反,它们是寄存器文件中的特定插槽,作为函数堆栈框架的一部分分配-本质上它们是虚拟寄存器。稍后我们将看到,字节码可以指定这些输入和输出寄存器,它们的参数将对其进行操作。
Ignition由一组字节码处理程序组成,这些处理程序是用高级的、与机器无关的汇编代码编写的。这些处理程序由CodeStubAssembler类实现,并在编译浏览器时使用TurboFan的后端进行编译。总的来说,每个处理程序处理一个特定的字节码,然后分派到下一个字节码各自的处理程序。
可以在下面看到LdaZero或“累加器加载零”字节码处理程序。v8/src/interpreter/interpreter-generator.cc可以看到。
1 | // LdaZero |
当V8创建一个新的隔离时,它将从构建时创建的快照文件中加载处理程序。该隔离还将包含一个全局解释器分派表,其中包含指向每个字节码处理程序的代码对象指针,由字节码值索引。通常,这个调度表只是一个枚举。
为了让Ignition运行字节码,JavaScript函数首先被BytecodeGenerator从其AST转换为字节码。该生成器遍历AST,并通过调用GenerateBytecode函数为每个AST节点发出适当的字节码。
然后,该字节码与称为SharedFunctionInfo对象的属性字段中的函数(JSFunction对象)相关联。之后,JavaScript函数code_entry_point 被设置为InterpreterEntryTrampoline内置存根。
当调用JavaScript函数时,输入了InterpreterEntryTrampoline ,并且负责设置适当的解释器堆栈帧,同时还将其派遣到解释器的字节码处理程序,以获取该函数的第一个字节码。然后,Ignition在v8/src/builtins/x64/builtins-x64.cc 源文件中处理函数执行或“解释”。
特别是在builtins-x64中的第1255 - 1387行。Builtins::Generate_InterpreterPushArgsThenCallImpl和Builtins::Generate Builtins::Generate_InterpreterPushArgsThenConstructImpl函数负责通过将参数和函数状态压入堆栈来进一步构建解释器堆栈框架。
我不会对字节码生成器进行过多的介绍,但是如果您想扩展您的知识,那么我建议您阅读Ignition Design Documentation: Bytecode Generation部分,以更好地理解它在底层是如何工作的。在这一节中,我想关注的是函数的寄存器分配和堆栈帧创建。
那么该堆栈框架如何生成?
好吧,在ByteCode生成期间,ByteCodeGenerator还将在函数寄存器文件中分配寄存器,以用于本地变量,上下文对象指针和表达评估所需的临时值。
Interleterentrytrampoline存根在堆栈框架的初始建筑上,然后在堆栈框架中为寄存器文件分配空间。该存根还将undefined 写入此寄存器文件中的所有寄存器,以使垃圾收集器(GC)在遍历堆栈时不会看到任何无效(即未标记)指针。
字节码将通过在其操作数中指定这些寄存器对这些寄存器进行操作,然后Ignition 将从与寄存器关联的特定堆栈插槽中加载或存储数据。由于寄存器索引直接映射到函数堆栈框架插槽,因此Ignition可以直接访问堆栈上的其他插槽,例如上下文和随函数传递的参数。
可以在下面看到一个函数堆栈框架的示例(如Chromium团队提供)。注意“Interpreter Stack Frame”。这是由Intersentrytrampoline构建的堆栈框架。
如您所见,我们具有红色的函数参数,以及绿色的局部变量用于表达评估的临时变量。
浅绿色部分包含隔离的当前上下文对象,调用者指针计数器和指向JSFunction对象的指针。该指向JSFunction的指针也被称为闭合(closure),它链接到函数上下文,SharedFunctionInfo对象以及 FeedbackVector等其他访问者。在下面可以看到此JSFunction在内存中的样子的一个示例。
您可能还注意到堆栈帧中没有累加寄存器。原因是累加器寄存器在函数调用期间会不断变化,在这种情况下,它作为状态寄存器保存在解释器中。这个状态寄存器由Frame Pointer(FP)指向,它还保存堆栈指针和帧计数器。
回到第一个堆栈帧示例,您还会注意到有一个Bytecode Array指针。这个BytecodeArray表示堆栈框架中特定函数的解释器字节码序列。最初每个字节码都是一个枚举,其中字节码的索引存储相应的处理程序——如前所述。
该BytecodeArray 的一个示例可以在 v8/src/objects/code.h中看到,并在下面提供该代码的摘要。
1 | // BytecodeArray represents a sequence of interpreter bytecodes. |
如您所见,GetFirstBytecodeAddDress函数负责在数组中获取第一个字节码地址。那么如何找到该地址?
好吧,让我们快速查看为var num = 42生成的字节码。
1 | d8> var num = 42; |
不用担心这些字节模型的含义,我们会稍作解释。看看字节码数组中的第一行,它存储了ldaconstant。在它的左侧,我们看到13 00。十六进制号0x13是字节枚举枚举器,代表该字节码的处理程序所在的位置。
一旦收到,将使用字节码,操作数和处理程序枚举来调用SetBytecodeHandler()。此函数在v8/src/interpreter/interpreter.cc文件中;该函数的一个示例如下所示。
1 | void Interpreter::SetBytecodeHandler(Bytecode bytecode, |
如您所见,dispatch_table_[index]将从存储在物理寄存器中的调度表中计算字节码的索引,最终将启动或最终确定dispatch()函数以执行字节码。
字节码数组还包含一个称为“常数池指针”的东西,该数组存储在生成字节码(例如字符串和整数)中引用为常数的堆对象。常量池是指向Heap Objects的指针的FixedArray。可以在下面看到此ByteCodeArray指针及其常量池堆的一个示例。
在我们继续之前,我想提到的另一件事是,InterpreterEntryTrampoline 存根具有一些固定的机器寄存器,这些寄存器已被Ignition使用。这些寄存器位于v8/src/codegen/x64/register-x64.h文件中。
这些寄存器的示例可以在下面看到,并将注释添加到感兴趣的示例中。
1 | // Define {RegisterName} methods for the register types. |
既然我们理解了这一点,现在是时候深入研究V8字节码的样子以及字节码操作数如何与寄存器文件交互。
理解V8的字节码
如第1部分中所述,V8中有几百个字节码,并且它们均在 v8/src/interpreter/bytecodes.h头文件中定义。正如我们将在一会儿看到的那样,这些字节码的每一个都指定其输入和输出操作数作为寄存器文件的寄存器。此外,许多opcodes以lda或sta开始,其中a代表累加器。
例如,让我们遵循ldasmi的字节码定义:
1 | V(LdaSmi, ImplicitRegisterUse::kWriteAccumulator, OperandType::kImm) |
正如你所看到的,LdaSmi将加载(因此称之为Ld)一个值到累加器寄存器。在这种情况下,它将加载一个kImm操作数,它是一个有符号字节,它与字节码名称中的Smi或Small Integer一致。总之,这个字节码将把一个小整数加载到累加器寄存器中。
请注意,在 v8/src/interpreter/bytecode-operands.h头文件中定义了操作数及其类型的列表。
因此,有了这些基本信息,让我们看一下实际的JavaScript函数的某些字节码。首先,让我们使用-print-bytecode标志启动D8,以便我们可以看到字节码。完成此操作后,只需输入一些随机的JavaScript代码,然后按Enter几次。原因是因为V8是“惰性”引擎,因此它不会编译不需要的东西。但是,由于我们首次使用字符串和数字,因此它将编译诸如Stringify之类的库,这首先会导致大量输出。
完成后,让我们创建一个名为incX 的简单JavaScript函数,该函数将递增对象的X属性,然后将其返回给我们。该功能应该看起来像是这样。
1 | function incX(obj) { return 1 + obj.x; } |
这将生成一些字节码,但我们不必担心。现在,让我们用赋值给属性x的对象调用该函数,并查看生成的字节码。
1 | d8> incX({x:13}); |
我们将忽略大部分输出,只关注字节码部分。但在此之前,请注意这个字节码位于SharedFunctionInfo对象中,这与我们之前的解释一致!首先,我们看到调用LdaSmi将一个小整数加载到累加器寄存器中,该值为1。
接下来,我们调用Star0,它将存储(因此称之为st)累加器中的值(根据a)到寄存器r0。在这种情况下,我们把1移到r0。
GetNameProperty字节码从a0中获取一个命名属性,并将其存储在累加器中,累加器的值为13。a0表示函数的第i个参数。因此,如果我们传入a,b,x,并且我们想加载x,字节码操作数将声明a2,因为我们是函数中的第二个参数(记住这是一个参数数组)。在这种情况下,a0将在表中查找索引0映射到x的命名属性。
1 | - length: 1 |
简而言之,这是加载obj.x的字节码。另一个[0]操作数被称为反馈向量,其中包含运行时信息和对象形状数据,用于通过Turbofan进行优化。
接下来,我们将寄存器R0中的值添加到累加器中,导致值为14。最后,我们调用返回返回累加器值的返回,然后退出函数。
为了帮助您在堆栈框架上可视化它,我提供了每种字节码指令中简化堆栈中发生的情况的GIF。
正如您所看到的,虽然字节码有点神秘,但一旦我们掌握了每个字节码的功能,就很容易理解和理解了。如果你想了解更多关于V8的字节码,我建议阅读JavaScript bytecode V8 Ignition Instructions,其中涵盖了大量不同的操作。
Sparkplug
现在我们已经很好地理解了Ignition是如何以字节码的形式生成和执行JavaScript代码的,是时候开始研究V8编译器工作流程的编译部分了。我们将从Sparkplug开始,因为它很容易理解,因为它只为优化目的只对已经生成的字节码和堆栈进行了很小的修改。
正如我们在第1部分中所知道的,Sparkplug是V8的非常快的非优化编译器,位于Ignition和TurboFan之间。从本质上讲,Sparkplug并不是一个真正的编译器,而更像是一个转换编译器,它将Ignitions 字节码转换为机器代码,以便在本机运行。此外,它是一个非优化编译器,所以它不会做非常具体的优化,因为TurboFan会做。
那么,是什么让Sparkplug这么快?Sparkplug 跑得快是因为它作弊。它编译的函数已经被编译成字节码,正如我们所知,Ignition已经完成了变量识别、控制流等的艰苦工作。在这种情况下,Sparkplug从字节码而不是JavaScript源代码编译。
其次,Sparkplug不像大多数编译器那样产生任何中间表示(IR)(我们将在后面学习)。在这种情况下,Sparkplug在字节码上的一次线性传递中直接编译为机器代码。这通常称为1:1映射。
有趣的是,SparkPlug几乎只是循环中的一个switch语句,它可以分发固定字节码,然后生成机器代码。我们可以在v8/src/baseline/baseline-compiler.cc 源文件中看到此实现。
下面是Sparkplug机器代码生成函数的示例。
1 | switch (iterator().current_bytecode()) { |
那么SparkPlug如何生成此机器代码?好吧,当然,它可以通过再次作弊来做到这一点。SparkPlug自身生成了很少的代码,而是SparkPlug仅调用通常由InterpreterEntryTrampoline输入的字节码内置,然后在v8/src/builtins/x64/builtins-x64.cc中处理。
如果您还记得在讨论Ignition时的JSFunction对象,就会记得闭包链接到优化的代码。本质上,Sparkplug将存储内建的字节码,当函数执行时,我们直接调用内建的字节码,而不是分派到字节码。
在这一点上,您可能会认为Sparkplug本质上是一个美化的解释器,您不会错。Sparkplug基本上只是通过调用相同的内置程序来序列化解释器的执行。但是这允许JavaScript函数更快,因为通过这样做,我们可以避免解释器的开销,如操作码解码和字节码调度查找——允许我们通过从模拟引擎转移到本地执行来减少CPU的使用。
要了解更多关于这些内置程序是如何工作的,我建议阅读“Short Builtin Calls”。
1:1 Mapping
Sparkplug的1:1映射并不仅仅涉及到如何将点火的字节码编译到它的机器代码变体;它也与堆栈框架有关。我们知道,编译器管道的每个部分都需要存储函数状态。正如我们在V8中已经看到的,JavaScript函数的状态通过存储当前被调用的函数、被调用的上下文、传递的参数数量、指向字节码数组的指针等等,存储在Ignition的堆栈帧中。
现在,众所周知,Ignition 是一个基于寄存器的解释器,它具有用于函数参数的虚拟寄存器,作为bytecode操作数的输入和输出。为了使SparkPlug快速并避免必须自己进行任何寄存器分配,它重新使用Ignitions 寄存器框架,从而允许SparkPlug镜像解释器的行为和堆栈。这允许SparkPlug在两个帧之间不需要任何形式的映射 - 使这些堆栈帧几乎兼容。
请注意,我说几乎1:1兼容,Ignition 和Sparkplug 堆栈框架有一个小差异。这个区别是Sparkplug不需要在寄存器文件中保留字节码偏移槽,因为Sparkplug代码直接从字节码发出。相反,它用缓存的反馈向量替换它。
这两个堆栈框架比较的例子可以在下面的图像中看到-由Ignition文档提供。

那么为什么Sparkplug需要创建和维护一个类似于Ignitions的堆栈框架布局呢?一个原因,也是Sparkplug 和Turbofan 工作的主要原因,通过做一些叫做 on-stack replacement (OSR)的事情。OSR是将当前正在执行的代码替换为不同版本的能力。在这种情况下,当Ignition看到一个JavaScript函数被大量使用时,它会将其发送给Sparkplug以加快速度。
一旦Sparkplug将字节码序列化到它们的内置程序中,它将替换特定函数的Interpreters堆栈框架。当堆栈被遍历并执行时,代码将直接跳转到Sparkplug中,而不是在Ignitions 模拟堆栈上执行。由于帧是“镜像”的,这在技术上允许V8在解释器和Sparkplug代码之间进行交换,几乎没有帧转换开销。
在我们继续之前,我只想指出Sparkplug的安全方面。一般来说,生成的代码本身不太可能存在安全问题。Sparkplug更大的安全风险在于如何解释ignions堆栈框架的布局,这可能导致类型混淆或堆栈上的代码执行。
这方面的一个例子是 Issue 1179595,由于无效的寄存器计数检查,这是一个潜在的RCE。在Sparkplug进行RX/WX位翻转的方式中也有一个问题-但我不会详细说明,因为这真的不重要,而且这样的bug在整个系列中不发挥重要作用。
好了,我们了解Ignition 和Sparkplug 的工作原理了。现在,是时候深入研究编译器工作流程和理解优化编译器TurboFan了。
TurboFan
TurboFan是V8的JIT (Just-In-Time)编译器,它结合了一个有趣的即时表示概念,即“节点海”(Sea of Nodes)和一个多层翻译和优化管道,帮助TurboFan从字节码生成质量更好的机器代码。对于那些一直在阅读代码和文档的人来说,你会知道TurboFan不仅仅是一个编译器。
TurboFan实际上负责解释器生成字节码后的处理程序,内置程序,代码存根,以及通过宏汇编的内联缓存系统!所以当我说TurboFan是编译器管道中最重要的部分时,我不是在开玩笑。
那么,像TurboFan这样的优化编译器是如何工作的呢?
优化编译器是通过所谓的“分析器”来工作的——我们在第1部分中简要提到过。本质上,这个分析器通过提前观察需要优化的代码(我们将此代码或JavaScript函数称为“热”)。它通过从JavaScript函数和堆栈中收集元数据和“样本”来做到这一点,通过查看inline caches和反馈向量收集的信息。
然后,编译器构建一个中间表示(IR)数据结构,用于生成优化的代码。监视代码,然后编译机器代码的整个过程称为即时编译或JIT编译。
即时编译(JIT)
正如我们所知,在解释器VM中执行字节码比在本机上执行汇编要慢。这是因为JavaScript是动态的,有很多属性查找、对象、值检查等开销,而且我们还在模拟堆栈上运行。
当然,映射和内联缓存(IC)通过加速属性、对象和值的动态查找来帮助解决这些开销——但它们仍然不能提供最佳性能。这是因为每个IC都是独立运行的,它不了解或不了解它的邻居。
以Maps为例,如果我们向已知形状添加属性,我们仍然必须依据转换表并查找或添加其他形状。如果我们必须为一个特定的函数或对象反复这样做,即使是已知的形状,我们也会一次又一次地这样做,浪费了大量的计算周期。
因此,当有一个JavaScript函数被执行了很多次时,可能值得花时间将该函数传递到编译器并将其编译为机器代码,以使其执行得更快。
例如,让我们以这段代码为例:
1 | function hot_function(obj) { |
hot_function简单地接受一个对象并返回属性x的值。接下来,我们执行该函数大约10k次,对于每个对象,我们只是传递给属性x一个的新整数。在这种情况下,因为函数被使用了很多次,而且对象的一般形状没有改变,V8可能会决定将它传递到管道(称为“层”)进行编译更好一些,以便执行得更快。
通过使用--trace-opt标志跟踪优化,我们可以在d8中的操作中看到这一点。那么,让我们这样做,同时,添加--allow-natives-syntax命令,这样我们就可以探索优化前后函数代码的样子。
我们首先启动d8,然后设置我们的函数。然后,对hot_function使用%DisassembleFunction查看它的类型。你应该得到类似的结果。
1 | d8> function hot_function(obj) {return obj.x;} |
正如你所看到的,最初这个代码对象将由Ignition执行,因为它是一个BUILTIN ,并将由我们所知道的InterpreterEntryTrampoline处理。现在,如果我们执行这个函数10k次,我们会看到它被TurboFan优化了。
1 | d8> for (let i=0; i < 10000; i++) {hot_function({x:i});} |
如您所见,TurboFan启动并开始编译函数进行优化。注意优化跟踪中的几个关键点。正如您在opt跟踪的第一行中所看到的,我们正在标记JSFunction的SFI或SharedFunctionInfo以进行优化。
如果您还记得我们对Ignition的深入研究,您就会记得SFI包含了我们函数的字节码。TurboFan将使用该字节码生成IR,然后将其优化为机器代码。
现在,如果你再往下看,你会看到OSR或栈上替换。TurboFan在优化字节码时做的事情和Sparkplug差不多。它将用真正的JIT或系统堆栈框架替换堆栈框架,该堆栈框架将在运行时指向优化的代码。这允许函数在下次调用时直接转到优化的代码,而不是在ignations模拟堆栈中执行。
如果我们再次对我们的hot_function运行%DisassembleFunction,我们应该看到它现在是优化的,并且SharedFunctionInfo中的代码入口点将指向优化的机器代码。
1 | d8> %DisassembleFunction(hot_function) |
对于那些目光敏锐的人来说,当我们追踪函数的优化时,您可能会注意到一些有趣的事情。如果你仔细观察,你会发现TurboFan并没有立即启动,而是在几秒钟之后——或者在循环了几千次之后。为什么呢?
发生这种情况的原因是因为TurboFan等待代码“预热”。如果你还记得我们关于Ignition 和Sparkplug的讨论,我们简要地提到了反馈向量 feedback vector。这个向量存储对象运行时数据以及来自内联缓存的信息,并收集所谓的**类型反馈**。
这对于TurboFan来说非常重要,因为我们知道JavaScript是动态的,我们无法存储静态类型信息。其次,直到运行时我们才知道值的类型。JIT编译器实际上必须对它编译的代码的使用和行为做出有根据的猜测,比如函数类型是什么,传入的变量类型等等。本质上,编译器做了很多假设或“推测”。
这就是为什么优化编译器会查看内联缓存收集的信息,并使用反馈向量来帮助做出明智的决定,决定需要对代码做什么以使其更快。这就是所谓的推测优化。
推测优化和类型保护
那么推测性优化如何帮助我们将JavaScript代码转换为高度优化的机器代码呢?为了解释这一点,让我们从一个例子开始。
假设我们对一个名为add的函数有一个简单的求值,例如return 1 + i。这里我们通过向i加1来返回一个值。在不知道i是什么类型的情况下,我们需要遵循ECMAScript标准实现来实现EvaluateStringOrNumericBinaryExpression的运行时语义。

如您所见,一旦计算了左右引用,并对操作数的左右值都调用了GetValue,然后需要按照ECMAScript标准调用ApplyStringOrNumericBinaryOperator,以便返回我们的值。
如果你还不清楚,在不知道变量i的类型的情况下,不管是整数还是字符串,我们不可能在几条机器指令中实现整个计算过程,而且还要速度很快。
这就是推测性优化出现的地方,TurboFan将依赖反馈向量对i可能的类型做出假设。
例如,如果在运行了几百次之后,我们查看Add字节码的反馈向量,并且知道i是一个数字,那么我们就不必处理 ToString或甚至ToPrimitive 求值。在这种情况下,优化器可以接受IR指令,并声明i和返回值只是数字,并以此装载它。这样可以最大限度地减少我们需要生成的机器指令。
那么在我们的函数中这些反馈向量是什么样的呢?
如果您还记得前面提到的JSFunction对象或闭包,就会记得闭包将我们链接到反馈向量槽slot 以及SharedFunctionInfo。在反馈向量中,有一个有趣的槽名为BinaryOp槽,它记录关于二元操作(如+、-、*等)输入和输出的反馈。
我们可以通过对add函数运行%DebugPrint来检查反馈向量内的内容,并查看这个特定的槽。您的输出应该与我的类似。
1 | d8> function add(i) {return 1 + i;} |
这里有几件有趣的东西。调用计数显示了我们运行add函数的次数,如果我们查看反馈向量,你会看到我们只有一个槽,也就是我们讨论过的BinaryOp。查看该槽,我们看到它包含当前反馈类型SignedSmall,它本质上指的是一个SMI。
请记住,这些反馈信息不是由V8解释的,而是由TurboFan解释的,正如我们所知,SMI是一个带符号的32位值,我们在本系列第1部分的指针标记部分中解释过。
总的来说,这些通过反馈向量的推测有助于加快我们的代码,因为它消除了不同类型的不必要的机器指令。不幸的是,仅仅针对一种类型的指令应用于动态对象是非常不安全的。
那么,如果在优化函数的中间我们传递的是一个字符串而不是一个数字,会发生什么?从本质上讲,如果发生这种情况,我们就会面临类型混淆的漏洞。为了防止潜在的错误假设,TurboFan在执行特定指令之前预先添加了一种类型保护。
该类型保护检查以确保我们传递的对象的Shape是正确的类型。这是在对象到达优化操作之前完成的。如果对象不匹配预期的Shape,那么优化代码的执行就不能继续。在这种情况下,我们将“跳出”汇编代码,并跳回解释器内未优化的字节码,并在那里继续执行。这就是所谓的“反优化”。
在优化后的汇编代码中,可以看到一个类型保护和跳转到反优化的示例。
1 | REX.W movq rcx,[rbp-0x38] ; Move i to rcx |
现在,由于类型保护而导致的反优化不仅仅局限于检查对象类型是否不匹配。他们也对算术运算和边界检查。
例如,如果我们优化的代码针对32位整数的算术运算进行了优化,并且存在溢出,我们可以反优化并让Ignition处理计算——从而保护我们免受机器上潜在的安全问题影响。这种可能导致反优化的问题被称为“副作用”(稍后我们将更详细地介绍)。
与优化过程一样,我们也可以通过使用--trace-deopt标志在d8中看到反优化的作用。一旦完成,让我们重新添加add函数并运行下面的循环。
1 | for (let i=0; i<10000; i++) { |
这将简单地让函数针对数字进行优化,然后在7k次迭代之后,我们将开始传递一个字符串——这应该会触发bailout。您的输出应该与我的类似。
1 | d8> function add(i) {return 1 + i;} |
如你所见,函数得到了优化,之后我们触发了bailout。由于在调用期间类型不符,这会将代码反优化回字节码。然后,有趣的事情发生了。函数再次得到优化。为什么?
好吧,这个函数仍然很“热”,还有几千次迭代要进行。现在,TurboFan在类型反馈中收集了数字和字符串,它将做的是,它将返回并第二次优化代码。但是这次它将添加允许字符串求值的代码。在这种情况下,将添加第二种类型的保护-因此第二次运行的代码现在同时针对数字和字符串进行了优化!
一个很好的例子和解释可以在视频 “Inside V8: The choreography of Ignition and TurboFan”中看到。
我们还可以通过对add函数运行%DebugPrint命令,在BinaryOp插槽中看到更新后的反馈。您应该会看到如下所示的内容。
1 | d8> %DebugPrint(add) |
如你所见,BinaryOp现在存储的反馈类型为Any,而不是SignedSmall和String。为什么?这是由于反馈格栅。
反馈格栅
反馈格栅存储一个操作可能的反馈状态。它从None开始,这表明它没有看到任何东西,它向下走向Any状态,这表明它看到了输入和输出的组合。Any状态表明该函数被认为是多态的,而相反,任何其他状态表明该函数是单态的——因为它只产生了某个值。
如果您想了解更多关于单态代码和多态代码之间的区别,我强烈建议您阅读“单态代码是怎么回事?”这篇精彩的文章。
下面,我为您提供了一个反馈格的大致外观的可视化示例。
就像第1部分中的数组格栅一样,这个格栅的工作方式相同。反馈只能在晶格中向下发展。一旦我们从Number到Any,我们就再也回不去了。如果我们确实因为某些神奇的原因返回,那么我们就有可能进入所谓的反优化循环,在这个循环中,优化编译器消耗无效的反馈,并不断地从优化的代码中退出。
你可以在v8/src/compiler/use-info.h文件中看到更多关于类型检查的信息。另外,如果你想了解更多关于V8的反馈系统和内联缓存,我建议你看“V8 and How It Listens to You - Michael Stanton”.。
“节点海”中间表示(IR)
现在我们知道了如何为TurboFan收集类型反馈来做出推测性假设,让我们看看TurboFan是如何根据这些反馈构建其专用IR的。生成IR的原因是由于该数据结构从代码复杂性中抽象出来,从而更容易进行编译器优化。
现在,TurboFans “节点海”IR是基于静态单赋值static single assignment 或SSA,这是IR的一个属性,要求每个变量在使用之前精确地赋值一次并定义。这对于消除冗余 redundancy elimination.等优化非常有用。
下面是前面示例中add函数的SSA示例。
1 | // function add(i) {return 1 + i;} |
然后将这种SSA形式转换为图形格式,该格式类似于控制流图(CFG),其中使用节点和边来表示代码及其在计算之间的依赖关系。这种图形形式允许TurboFan将其用于数据流分析和机器代码生成。
那么,让我们看看结点海是什么样子的。我们将使用我们的hot_function示例。首先创建一个新的JavaScript文件,并向其中添加以下内容。
1 | function hot_function(obj) { |
一旦完成,我们将通过d8运行这个脚本,使用--trace-turbo标志,它允许我们跟踪和保存TurboFans JIT生成的IR。您的输出应该与我的类似。在运行结束时,它应该生成一个具有turbo-*. JSON命名约定的JSON文件。
1 | C:\dev\v8\v8\out\x64.debug>d8 --trace-turbo hot_function.js |
完成后,在web浏览器中导航到Turbolizer,按CTRL + L并加载JSON文件。这个工具将帮助我们可视化由TurboFan生成的节点海图。
你看到的图表应该和我的差不多。
在Turbolizer中,左边你会看到你的源代码,右边(没有显示在图像中)你会有优化的机器代码,由TurboFan生成。在中间你会看到一个结点海图。
目前有很多节点隐藏,只有控制节点显示出来,这是默认的行为。如果您单击“刷新”符号右侧的“显示所有节点”框,您将看到所有节点。
通过在Turbolizer中闲逛并查看图表,你会注意到有五种不同颜色的节点,它们表示如下:
- 黄色:这些节点代表控制节点,意味着任何可以改变脚本“流”的东西——比如if/else语句。
- 浅蓝色:这些节点表示某个节点可以拥有或返回的值,例如堆常量或内联值。
- 红色:表示JavaScript重载操作符的语义,例如在JavaScript级别执行的任何操作,例如JSCall、JSAdd等。这些类似于字节码操作。
- 蓝色:表示vm级操作,例如分配、绑定检查、从堆栈加载数据等。这有助于跟踪反馈被涡扇消耗。
- 绿色:这些对应于单机级指令。
正如我们所看到的,这个节点海中的每个节点都可以表示算术操作、加载、存储、调用、常量等。然后有三条边(由每个节点之间的箭头表示),我们需要知道它们表示依赖关系。这些边是:
- 控件:就像在CFG中一样,这些边启用分支和循环。
- 值:就像数据流图一样,这些图显示值依赖关系和输出。
- 效果:详细说明顺序操作,如读或写状态。
有了这些知识,让我们稍微扩展一下图,看看其他几个节点,以理解流是如何工作的。请注意,我隐藏了一些并不真正重要的选择节点。

正如我们所看到的,黄色节点是管理函数流的控制节点。最初我们有一个loop节点,它告诉我们我们正在进入一个循环。从那里,控制边指向Branch和LoopExit节点。分支就是它的意思,它将循环“分支”为True/False语句。
如果我们跟随Branch节点向上,我们将看到它有一个SpeculativeNumberLessThan节点,它有一个值边指向值为10000的NumberConstant。这与我们的函数是一致的,因为我们循环了10k次。因为这个节点是绿色,所以它是一条机器指令,表示循环的类型保护。
您可以从SpeculativeNumberLessThan节点中看到,有一个效果边指向LoopExitEffect,这意味着如果数字大于10k,我们将退出循环,因为我们刚刚打破了假设。
当值小于10k且SpeculativeNumberLessThan为真时,我们将加载对象,并调用JSDefineNamedOwnProperty,它将使对象偏移到属性x。然后我们调用JSCall将属性值加1并返回该值。从那个节点我们也有一个效果边到SpeculativeSafeIntegerAdd。该节点有一个value edge指向值为1的NumberConstant节点,这是我们在返回值时所做的数学加法。
再次注意,我们有一个SpeculativeSafeIntegerAdd节点,它检查以确保我们所做的加法运算确实添加了一个SMI,而不是其他东西,否则它将触发类型保护和反优化。
对于那些可能想知道Phi节点是什么的人来说,它基本上是一个SSA节点,它合并了由不同分支计算的两个(或多个)值的可能性。在这种情况下,它将两个潜在的整数猜测合并在一起。
如您所见,一旦了解了基础知识,理解这些图表就不太复杂了。
现在,如果你看一下节点海窗口的左上角,你会看到我们在V8.TFBytecodeGraphBuilder选项。这个选项向我们展示了从字节码生成的IR,而没有对其应用任何优化。从下拉菜单中,我们可以选择这段代码经过的其他不同优化过程,以查看相关的IR。
常规优化
好了,现在我们已经讨论了TurboFan的节点海,我们至少应该有一个体面的理解如何导航和理解生成的IR。从这里,我们可以深入了解一些常见的TurboFan优化。这些优化在本质上作用于由字节码产生的原始图。
由于类型保护,结果图现在具有静态类型信息,因此以更经典的提前方式进行优化,以提高代码的执行速度或内存占用。之后,一旦图形被优化,得到的图形就会被降为机器码(称为“lowering”),然后被写入可执行内存区域,供V8在调用编译后的函数时执行。
需要注意的一点是,lowering可以分多个阶段进行,中间还可以进一步优化,这使得这个编译器工作流程非常灵活。
话虽如此,让我们来研究一些常见的优化。
Typer
最早的优化阶段之一被称为TyperPhase,它由OptimizeGraph函数运行。此阶段跟踪代码并从堆对象标识操作的结果类型,例如Int32 + Int32 = Int32。
当type运行时,它将访问图的每个节点,并试图通过简化操作逻辑来“减少”它们。然后,它将调用节点的关联类型调用来将一个Type与它关联起来。
例如,在我们的例子中,循环中的常量整数和返回的算术将被Typer::Visitor::TypeNumberConstant访问,它将返回一个Range类型-可以从v8/src/compiler/types.cc中的代码示例中看到。
1 | Type Type::Constant(double value, Zone* zone) { |
那么我们的推测节点呢?
对于那些,它们由OperationTyper处理。在我们的例子中,返回值的算术推测将调用OperationTyper::SpeculativeSafeIntegerAdd,它将把类型设置为一个“安全整数”范围,例如Int64。该类型将被检查,如果在执行期间它不是Int64,我们将反优化。这在本质上允许算术操作具有正和负的返回值,并防止潜在的溢出/下溢问题。
了解了这些,让我们来看看V8.TFType优化阶段查看图和节点关联的类型。
Range Analysis
在Typer优化期间,编译器跟踪代码,识别操作范围并计算结果值的边界。这被称为极差分析。
如果您注意到上面的图,就会发现我们遇到了Range类型,特别是对于具有Int64变量范围的SpeculativeSafeIntegerAdd节点。这样做的原因是范围分析优化器计算添加或返回的值的最小值和最大值。
在我们的例子中,我们从对象的属性(x + 1)返回i的值。类型反馈只知道返回的值是一个整数,就这样,它从来不知道值的范围是什么。所以,为了安全起见,它决定赋予它最大的价值,以防止出现问题。
所以,让我们通过考虑下面的代码来再看一下这个范围分析:
1 | function hot_function(obj) { |
正如我们所看到的,根据传入的obj参数的类型,如果obj是一个等于单词leet的字符串,则a将等于1337,否则将等于13。这部分代码将通过SSA并合并到一个Phi节点,该节点将包含a的范围。常量的范围将被设置为它们的硬编码值,但由于算术计算,这些常量也会对我们的推测范围产生影响。
如果我们在范围分析之后查看这段代码生成的图形,我们应该会看到以下内容。
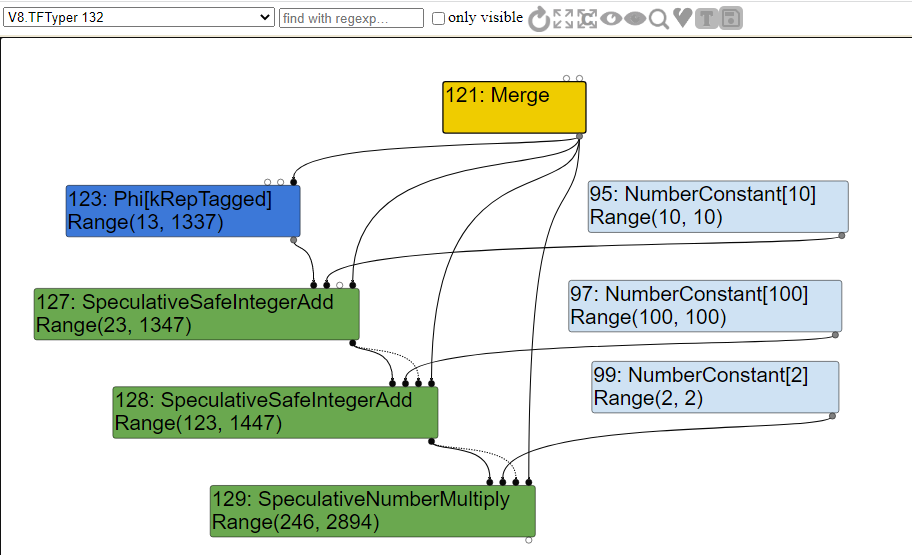
你可以看到,由于SSA,我们有了节点。在范围分析期间,类型访问TypePhi节点函数并创建操作数13和1337的并集,使我们能够获得a的可能范围。
对于推测节点,OperationTyper 调用AddRanger函数,该函数计算Range类型的最小和最大边界。在本例中,您可以看到,在算术运算之后,该类型计算了a的两个可能迭代的返回值的范围。
有了这个,在范围分析失败的情况下,我们得到一个编译器不期望的值,我们反优化。很容易理解!
边界检查消除
在简化lowering 阶段应用于Typer 的另一个常见优化是应用于CheckBound推测节点的CheckBounds操作。这种优化通常应用于数组访问操作,如果在范围分析之后,数组的索引已经被证明在数组的边界之内。
我之所以说“was”,是因为Chromium团队已经决定禁用这个优化,以 加强 TurboFan的边界检查,防止typer错误。有一些“bug”可以让您绕过加强的检查,但我不会深入讨论。如果你想了解更多关于这些错误,那么我建议阅读“Circumventing Chrome’s Hardening of Typer Bugs”。
不管怎样,让我们以以下代码为例来演示这种类型的优化是如何工作的:
1 | function hot_function(obj) { |
如您所见,这与我们在range分析中使用的代码非常相似。我们再次接受一个参数到我们的hot_function,如果对象匹配字符串“leet”,我们将a设置为2并返回值1337,否则我们将a设置为1并返回值13。
特别要注意的是,a永远不等于0,所以我们永远,或者至少应该永远不能返回0。当我们看图表的时候,这为我们创造了一个有趣的例子。那么,让我们看看IR的逸出分析部分,看看我们的图是什么样的。
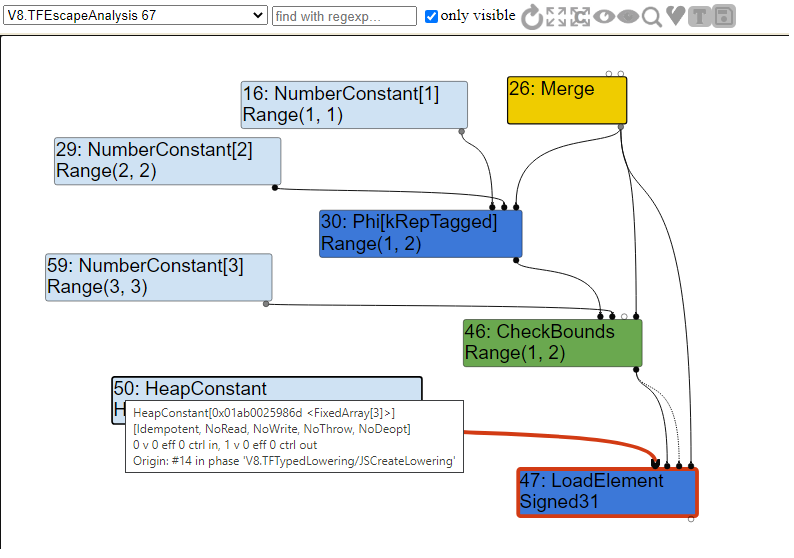
正如你所看到的,我们有另一个Phi 节点,它合并了a的潜在值,然后我们有CheckBounds节点,它用来检查数组的边界。如果我们在1或2的范围内,我们调用LoadElement从数组中加载我们的元素,否则我们将退出,因为边界检查不期望索引为0。
对于那些已经注意到它的人,您可能想知道为什么我们的LoadElement是Signed31类型而不是Signed32类型。简单地说,Signed31表示第一位用于表示符号。这意味着,在32位有符号整数的情况下,我们实际使用的是31位而不是32位。同样,我们可以看到LoadElement有一个长度为3的FixedArray HeapConstant的输入。这个数组就是我们的值数组。
一旦进行了逃逸分析,我们就进入简化的lowering 阶段。这个lowering 阶段(双关语)只是将所有的值表示改变为正确的机器表示,这是由机器操作员自己决定的。这个阶段的代码位于v8/src/compiler/simplified-lowering.cc中。在这一阶段中进行了边界检查消除。
那么,编译器如何决定使CheckBounds节点冗余呢?
对于每个CheckBounds节点VisitCheckBounds函数都会被调用。这个函数负责检查并确保索引的最小范围等于或大于零,并且它的最大范围不超过数组长度。如果检查为真,则触发一个DeferReplacement,标记该节点要删除。
在加固提交7bb6dc0e06fa158df508bc8997f0fce4e33512a5 之前的VisitCheckBounds函数示例如下所示。
1 | void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) { |
正如你所看到的,我们的CheckBound范围将落入if语句,其中range (1,2). min() >= 0和range (1,2). max() < 3。在这种情况下,上面图中的节点#46将成为冗余并被删除。
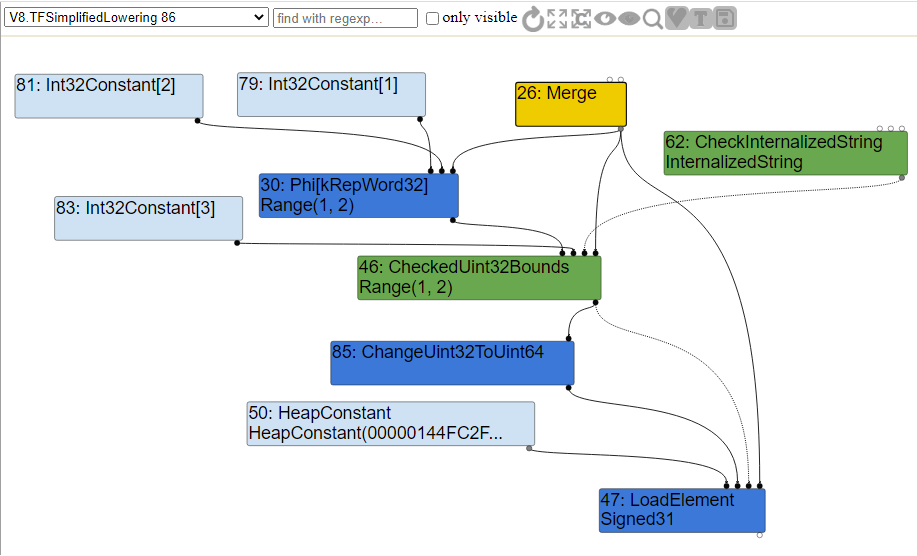
现在,如果您在提交之后查看更新的代码,您将看到轻微的更改。对DeferReplacement的调用已经被移除,取而代之的是我们用一个CheckedUint32Bounds节点替换了这个节点。如果检查失败,TurboFan调用kAbortOnOutOfBounds,中止绑定检查并崩溃,而不是去优化。
新代码如下所示:
1 | void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) { |
如果我们查看图的简化降低部分,我们确实可以看到CheckBounds节点现在已经按照代码被CheckedUint32Bounds节点所取代,所有其他节点的值都被降低为机器码表示。
冗余消除
另一种类似于BCE的流行优化类型称为冗余消除。它的代码位于v8/src/compiler/redundancy-elimination.cc,并负责删除多余的类型检查。RedundancyElimination类本质上是一个图减量器,它试图删除或组合Effect链中的冗余检查。
Effect链基本上就是加载函数和存储函数的效果边之间的操作顺序。例如,如果我们试图从一个对象加载一个属性并尝试修改它,例如obj[x] = obj[x] + 1,那么我们的Effect链将是JSLoadNamed => SpeculativeSafeIntegerAdd => JSStoreNamed。TurboFan必须确保这些节点的外部效果不会被重新排序,否则我们可能会有不适当的保护措施。
v8/src/compiler/graph-reducer.h中详细介绍了一个reducer,它试图根据给定节点的操作符和输入来简化它。有一些类型的约简,比如常量折叠constant folding,如果我们把两个常数相加,我们就会把它们折叠成一个,也就是说,3 + 5现在只是一个8的常量节点,还有强度约简,如果一个值加到一个节点上,没有任何影响,我们就会保留一个节点,即x + 0只会有一个节点x。
我们可以使用–trace_turbo_reduction标志来跟踪这些类型的缩减。如果我们带着这个标志从上面再次运行hot_function,您应该会看到这样的输出。
1 | C:\dev\v8\v8\out\x64.debug>d8 --trace_turbo_reduction hot_function.js |
这个标志有很多有趣的输出,正如你所看到的,有很多不同的简化和消除被执行。在这篇文章的后面,我们将简要地介绍其中的一些,但我希望你仔细看看其中的一些减法。
比如这个:
1 | In-place update of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) by reducer RedundancyElimination |
是的,你没看错CheckMaps被更新了,后来由于冗余消除减速器被替换了。发生这种情况的原因是冗余消除检测到CheckMaps调用是一个冗余检查,并在相同的控制流路径中删除了除第一个之外的所有检查。
在这一点上,我知道你们中的一些人可能会想,“这不是一个安全漏洞吗?”答案是“有可能”和“视情况而定”。
在我更详细地解释这一点之前,让我们看看下面的代码示例:
1 | function hot_function(obj) { |
如您所见,这段代码非常简单。它接收一个对象并返回属性a和属性b的值的和。如果我们查看type优化图,我们将看到以下内容。

如您所见,当我们进入函数时,首先调用CheckMaps来验证我们传递的对象的映射是否同时具有a和b属性。如果该检查通过,我们就调用LoadField从Parameter常量中加载偏移12,这是我们传入的obj对象的a属性。
在此之后,我们执行另一个CheckMaps调用来再次验证映射,然后加载属性b。完成此操作后,我们调用JSAdd函数来执行数字、字符串加法或两者相加。
这里的问题是冗余的CheckMaps调用,因为正如我们所知,我们传递进来的这个对象的映射不能在两个CheckMap操作之间改变。在这种情况下,它将被删除。
我们可以在简化Lower阶段的图表。看到这种冗余消除。
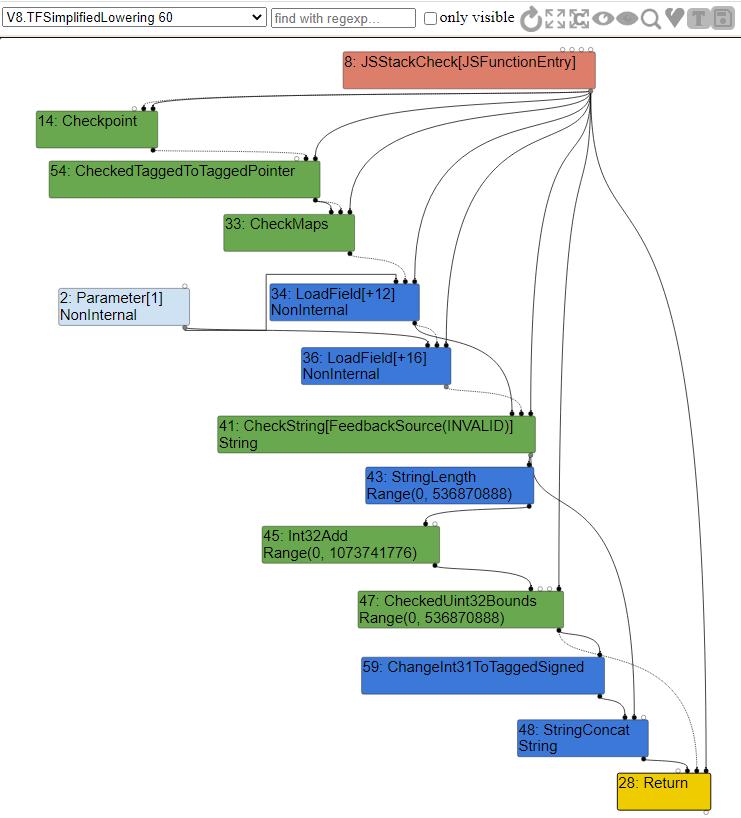
正如您可以清楚地看到的,第二个CheckMaps节点现在已经被删除,在第一次检查之后,我们只是一个接一个地加载两个属性——实际上加快了我们的代码。此外,由于简化了lowering,JSAdd调用已经降低到机器代码变体,以根据ECMAScript标准验证整数和字符串表达式。
回到我们的问题,这是否是一个安全漏洞。如前所述,“视情况而定”。这样做的原因是某些操作可能会对上下文的可观察执行造成副作用——这就是为什么我们有副作用链。如果TurboFan由于某种原因忘记考虑副作用,没有将其写入副作用链,那么对象的Map可能会在执行过程中发生变化,例如另一个用户函数调用修改对象或添加属性。
V8中的每个中间表示操作都有各种与之相关的标志。JavaScript操作符的一些标志的例子可以在v8/src/compiler/js-operator.cc中看到。一些这些标志有特定的假设。
例如,V(ToString, Operator::kNoProperties, 1,1)假设字符串应该没有属性。另一个例子如V(LoadMessage, Operator::kNoThrow | Operator::kNoWrite, 0,1)假设LoadMessage操作不会通过kNoWrite标志产生可观察到的副作用。这个kNoWrite标志实际上并不写入效果链。
正如您所看到的,如果我们可以让编译器删除一个看似认为没有副作用的操作的冗余检查,那么如果您可以在编译代码执行期间修改对象或属性,那么您就有一个潜在的可利用的错误。
关于冗余消除和副作用的主题最初可以扩展到讨论来自这些消除检查的错误如何导致可利用的漏洞。但在此之前,让我们快速地简单介绍一些其他常见的优化。
其他优化
正如之前从--trace_turbo_reduction标志的输出中看到的,在TurboFan中发生的优化比我们谈论的要多得多。我试图介绍与我们将在第3部分中利用的错误相关的最重要的优化,但我仍然想快速介绍其他一些优化,以便至少您对它们有一个大致的了解。
一些其他常见的优化,你会看到在TurboFan 如下:
- 控件优化:在
v8/src/compiler/control-flow-optimizer.cc中定义,通常这种优化工作在优化图的流程,并将某些分支链变成开关。 - 别名分析和全局值编号:别名分析确定存储节点和加载节点之间的依赖关系。因此,如果两个加载操作依赖于一个操作,则它们不能执行,直到第一个操作完成,即x = 2;Y = x + 2;Z = x + 2。GVN或全局值编号紧随suite,并删除冗余的Store和Load操作,即可以删除z = x + 2,并将z设置为y,因为该操作是冗余的。
- 无用代码消除(DCE):无用代码消除顾名思义。它只是遍历所有节点并删除不会执行的代码。例如,如果if语句的x和y始终为True或者False,则错误路径将被视为“死亡”并被删除。
如果你想了解更多关于不同优化和节点海洋的知识,我建议你阅读“TurboFan JIT Design”和“Introduction to TurboFan”。
常见JIT编译器漏洞
了解了完整的V8管道和编译器优化之后,我们现在可以开始研究和理解浏览器中存在哪些类型的漏洞类。正如我们所知,JavaScript引擎及其所有组件(如编译器)都是用c++实现的。
在这种情况下,管道首先容易受到常见内存和类型安全违规的影响,例如整数溢出和下溢、数组越界错误、超出边界的读写、缓冲区溢出、堆溢出,当然还有释放后使用UAF的错误等等。
除了常见的c++错误之外,由于推测性假设的性质,我们还可能在优化阶段出现逻辑错误和机器代码生成错误。这种逻辑错误可能源于对操作可能对对象或属性产生的潜在副作用的错误假设,或者源于删除关键类型保护的不当优化传递。
这些类型的问题通常被称为“类型混淆”漏洞,即编译器不会验证传递给它的对象的类型或形状,导致编译器盲目地使用对象。CVE-2018-17463就是这种情况,我们将在本博客的第3部分中尝试分析和利用它。
文章到这里,我考虑深入分析一些bug,并向您展示易受攻击的代码示例。最后,我决定不这么做。为什么?好了,文章到这里,您应该已经对浏览器内部结构和V8有了足够的了解,能够自己查看Chromium代码并理解某些错误报告。
这是给读者的一些作业。我将为您提供一个关于浏览器利用的视频和错误报告列表。花点时间阅读这些报告,并了解这些错误是如何产生的,以及是什么允许它们被利用。
请注意,其中一些错误存在于其他JavaScript引擎中,但无论如何,它们为您提供了所有JavaScript引擎中可能存在的漏洞的表示。
- 35C3 - From Zero to Zero Day: ChakraCore Type Confusion due to Invalid Side-Effects
- Browser Security Beyond Sandboxing - CVE-2017-5121
- Chrome TurboFan Remote Code Execution via Type Confusion
- CVE-2015-0817 - Incorrect asm.js Bounds Checking Elimination
- CVE-2016-1669 - Use After Free in RegExp
- CVE-2016-1677 - Type Confusion Leads to Info Leak in decodeURI
- CVE-2016-5129 - V8 Out of Bound Read in GC with Array Object
- CVE-2017-2547 - WebKit: Invalid Bounds Check leads to OOB Access
- CVE-2017-5040 - Information Leak in Array indexOf
- CVE-2018-0758 - Chakra: JIT: Missing Integer Overflow Check
- CVE-2018-0769 - Chakra JIT: Incorrect Bounds Calculation
- CVE-2018-4192 - Race Condition in Garbage Collection for array.reverse()
- CVE-2018-6065 - V8 Integer Overflow in Object Allocation Size
- CVE-2018-6106 - V8 AwaitedPromise Incorrect State
- CVE-2018-6136 - Crash with JavaScript RegExp Subclassing
- CVE-2018-6142 - Information Leak in Map Constructor
- [CVE-2019-5782 - Improper Side-Effect in Lowering Leads to OOB via Check Bounds Elimination](https://github.com/vngkv123/aSiagaming/blob/master/Chrome-v8-906043/Chrome V8 - -CVE-2019-5782 Tianfu Cup Qihoo 360 S0rrymybad- -ENG-.pdf)
- CVE-2019-13764 - Invalid NaN Type Check via Typer Optimizer
- CVE-2021-21220 - Improper JIT OpCode Leads to RCE
- Exploiting Chrome V8: Krautflare (35C3 CTF 2018)
- Exploiting TurboFan Through Bound Check Elimination
- Issue: 762847 - Off By One in Range Optimization of String.indexOf
- Patch Gapping Chrome - Properties Backing Store Type Confusion
- JavaScript Vulnerability Database
- ZDI Advisories Page
总结
这篇文章就是这么写的!感谢你坚持到最后,并阅读了所有这些内容,因为其中涵盖了很多复杂的材料。我甚至数不清有多少次我不得不在自己学习这些知识的同时,回头编辑这篇博客文章的初稿。
希望这里展示的很多材料都很容易理解。如果不是,那么就像我的第一篇文章一样,花点时间通读这篇文章,利用博客和参考资料部分的链接来帮助你理解一些不清楚的概念。
老实说,对我帮助最大的是通读和调试V8代码。这可以让您更好地了解在表面下发生了什么,以及所谓的where和when。如果您试图检查代码中的错误,这也有助于您更加熟悉代码。
不管怎样,通过我们在这里介绍的所有信息,优化部分将是我们在下一篇文章中最重要的部分。在本博客文章系列的第三部分中,我们将利用我们所知道的一切来分析和理解CVE-2018-17463。之后,我们将开始了解浏览器利用原语的基础知识,然后我们将仔细研究并实际利用该漏洞在系统上进行远程代码执行。
话虽如此,谢谢你的阅读,我们下一篇文章见!
荣誉
我衷心感谢maxpl0it对这篇文章进行了全面的技术审查,在发布之前提供了关键的反馈并添加了一些重要的细节。
我也要感谢Connor McGarr和V3ded花时间校对这篇文章的准确性和可读性。谢谢大家的宝贵时间!
最后,我想感谢Jeremy Fetiveau在Chrome开发领域的出色工作,并为《逆向工程师日记》撰写了如此详细的博客文章。这些帖子对理解Chrome和V8的许多细微差别非常有帮助。
参考链接
- An Introduction to Speculative Optimization in V8
- Circumventing Chrome’s Hardening of Typer Bugs
- Compiler Design: Static Single Assignment
- Deoptimization in V8
- Digging into the TurboFan JIT
- Exploiting TurboFan Through Bounds Check Elimination
- Firing up the Ignition interpreter
- Franziska Hinkelmann: JavaScript engines - how do they even?
- Getting Around the Chromium Source Code Directory Structure
- How To Start JIT-ting
- Ignition and TurboFan Compiler Pipeline
- Ignition Design Docs
- Ignition: Register Equivalence Optimization
- Intro to Chrome’s V8 from an Exploit Development Angle
- Introduction to TurboFan
- JavaScript engine fundamentals: optimizing prototypes
- JavaScript Engine Fundamentals: Shapes and Inline Caches
- Modern attacks on the Chrome browser : optimizations and deoptimizations
- Sea of Nodes
- Sigurd Scheider: Inside V8: The choreography of Ignition and TurboFan
- Sparkplug Design Documentation
- The Chromium Super (Inline Cache) Type Confusion
- TurboFan IR
- TurboFan JIT Design
- Understanding V8’s Bytecode
- V8 and How It Listens To You - Michael Stanton
- V8 release v6.8
- V8: Hooking up the Ignition to the TurboFan
- What’s up with Monomorphism?